Webdriver doesn’t recognize element attributes not part of the HTML definitions. So aria-xxxx and dojo-xxx attributes are much slower to locate in the DOM. Whenever one of the standard attributes can carry a unique value on the page that describes a business object or function directly understandable to a business user, automation will be easier and more robust.
And often the usual locators, like id and name, have generated values that can change with revision and sometimes dynamically with changes in loaded data.
Finding a key section, for example a data grid, in a large page can be a challenge, especially in an application taking advantage of one or more of the very powerful javascript libraries like jQuery, Dojo, and etc. Even more challenging are the generated ‘id’ addtribute values that are often used by these libraries. Our example uses Dojo.
Dojox data grids are powerful. Finding rows and columns in them can be challenging because they are not rendered inside a single encompassing table, but in a hierarchy of divs containing not just the header and data rows of the table. Other available widgets and features are included in skeleton form and not visible unless used.
The first challenge is to find the correct parent div for the desired grid. Dojo generates the id for each as dojox_grid_[Enhanced]Grid_ ending with a zero-based index, e.g., dojox_grid_Grid_0.
If there is a consistent unique string that will always appear in only the desired grid on the page, then two approaches work.
- Find the element with the text string and walk up the parent branch until you find the div with id matching /^dojox_grid_.*Grid_d+$/. The anchored regex pattern is needed as there are ids in the grid like ‘dojox_grid_EnhancedGrid_0Hdr0’ that might be in the direct lineage of the element with the target string.
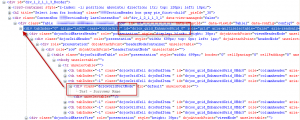
target = browser.element(:text, ‘Borrower Name’)
until target.id =~ /^dojox_grid_.*Grid_d+$/i do
target = target.parent
end
- Collect the divs with ids that match
/^dojox_grid_.*Grid_d+$/and grab the one which contains the unique text string. Note there is only one grid on the sample page
divs = browser.divs(:id, /^dojox_grid_.*Grid_d+$/i)
divs.each do |d|
if div.text.include?(‘Borrower Name’)
target = d
break
end
end
![]()
The first is usually quicker, as in this sample. Gathering a collection of elements based on a specific attribute value forces traversal of the entire dom. Searching directly for a text string allows the traversal to stop as soon as the string is located and walking up the parent branch is pretty quick.
Another way, in this example, is to take advantage of the header structure (actually part of the surrounding architecture rather than a Dojo structure) and target the section header that contains the grid we want.
section_div = browser.h2(:text, /Select Loan/).parent
target = section.div(:id, /^dojox_grid_.*Grid_d+$/i)
![]()
Ideally there should be something in the target division that allows locating it directly. In this case a title attribute containing ‘Search Results – Select Loan’ would work well.
target = browser.div(:title, ‘Search Results – Select Loan’)
