A Data-Driven testing framework refers to the repeating of the same test case scenario using different data sets – making the test case, data centric. As a result, a QA Engineer is able to test multiple scenarios using one single test case. This article will explain the anatomy of a Data-Driven test, followed by an example of a test we created to exemplify Data-Driven scripting. Cucumber inherently supports Data-Driven testing, so if you are scripting using Cucumber to write your scripts then it would be useful to know a tip that makes Data-Driven testing with Cucumber extremely easy, which can be found here.
Data-Driven Framework Anatomy
A Data-Driven script is parameterized, replacing hardcoded values with variables, in which the data may be loaded from a number of sources, including: the Gherkin file, text files, Excel files, CSV files and databases. Upon execution, the test case will read a data row, send that data to the script, and will repeat until there is no more data to be read. 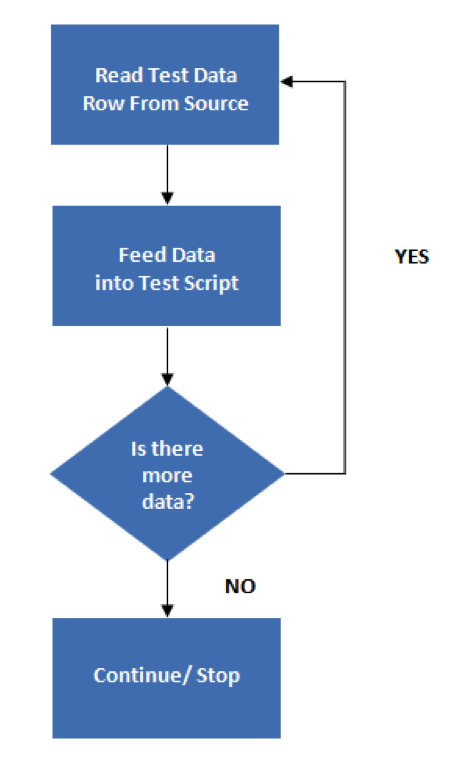 In this framework, test data is separated and kept outside of the test scripts, while test case logic resides inside test scripts. The data is then called upon by referencing the test data source in the script. Test scripts themselves are prepared using either the Linear or Structured Scripting framework. Test data is read from external files (Text files, Excel files, CSV files, ODBC sources, ADO objects, ADO objects) and are then loaded into the variables inside the test script. Variables are used for both inputting and verifying the values.
In this framework, test data is separated and kept outside of the test scripts, while test case logic resides inside test scripts. The data is then called upon by referencing the test data source in the script. Test scripts themselves are prepared using either the Linear or Structured Scripting framework. Test data is read from external files (Text files, Excel files, CSV files, ODBC sources, ADO objects, ADO objects) and are then loaded into the variables inside the test script. Variables are used for both inputting and verifying the values.
By keeping the test data and the test scripts separate this means that the test data is not hard coded into the test, and this allows for reusability and maintainability of the test. If the test data ever changes or needs to be updated then once the external file storing all of the information is updated there would be no need to rewrite the test, because it wouldn’t have been affected by that change. So the tests can be reused and can be updated whenever needed, and updated in a central location of the external file rather than having to go through all places where the file was used in the scripts.
Writing A Data-Driven Test
For this example we will be writing Login, & Create a Lead scenarios on Zoho.com. Using the Data-Driven Testing framework method would involve two steps:
Step 1: Creating the external test-data file (which could be Excel or any other database source). In our case for creating a lead, we will first be creating test data for logging in, which is an action used to conduct any test in Zoho (meaning it is very useful to have this action automated), and this is composed of a username and password: 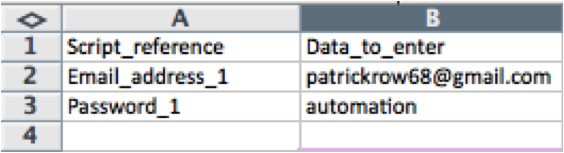 Then for filling in the new lead information we would need a phone number, billing address, billing state, etc., and our test data in our Excel spreadsheet looks like this:
Then for filling in the new lead information we would need a phone number, billing address, billing state, etc., and our test data in our Excel spreadsheet looks like this: 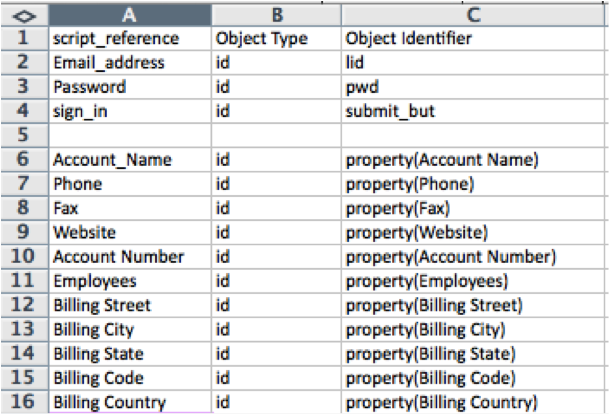 Step 2: Creating the test script and making references to your test-data source. Below is our script where in lines 9 and 34, you can see we have <Then I read the data from the spreadsheet>, in reference to our stored Excel test data.
Step 2: Creating the test script and making references to your test-data source. Below is our script where in lines 9 and 34, you can see we have <Then I read the data from the spreadsheet>, in reference to our stored Excel test data. 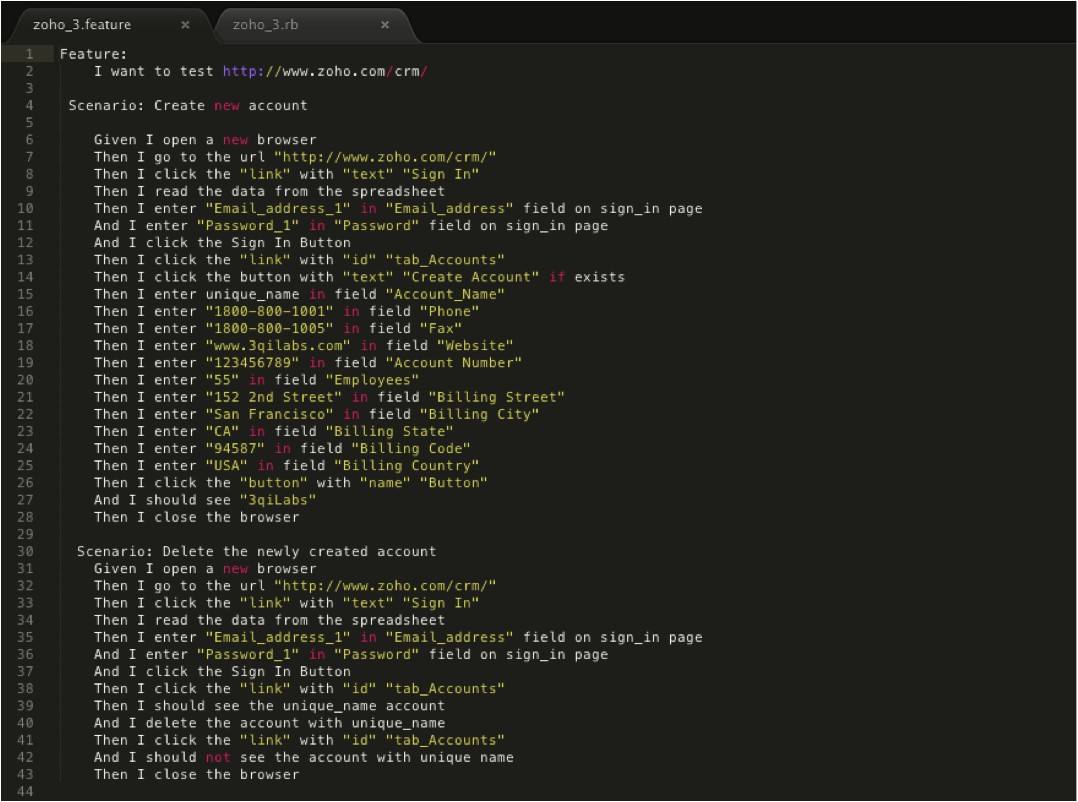 And the step definition file where each of the above steps is defined looks like this, where in line 53 our external Excel spreadsheet is referenced:
And the step definition file where each of the above steps is defined looks like this, where in line 53 our external Excel spreadsheet is referenced: 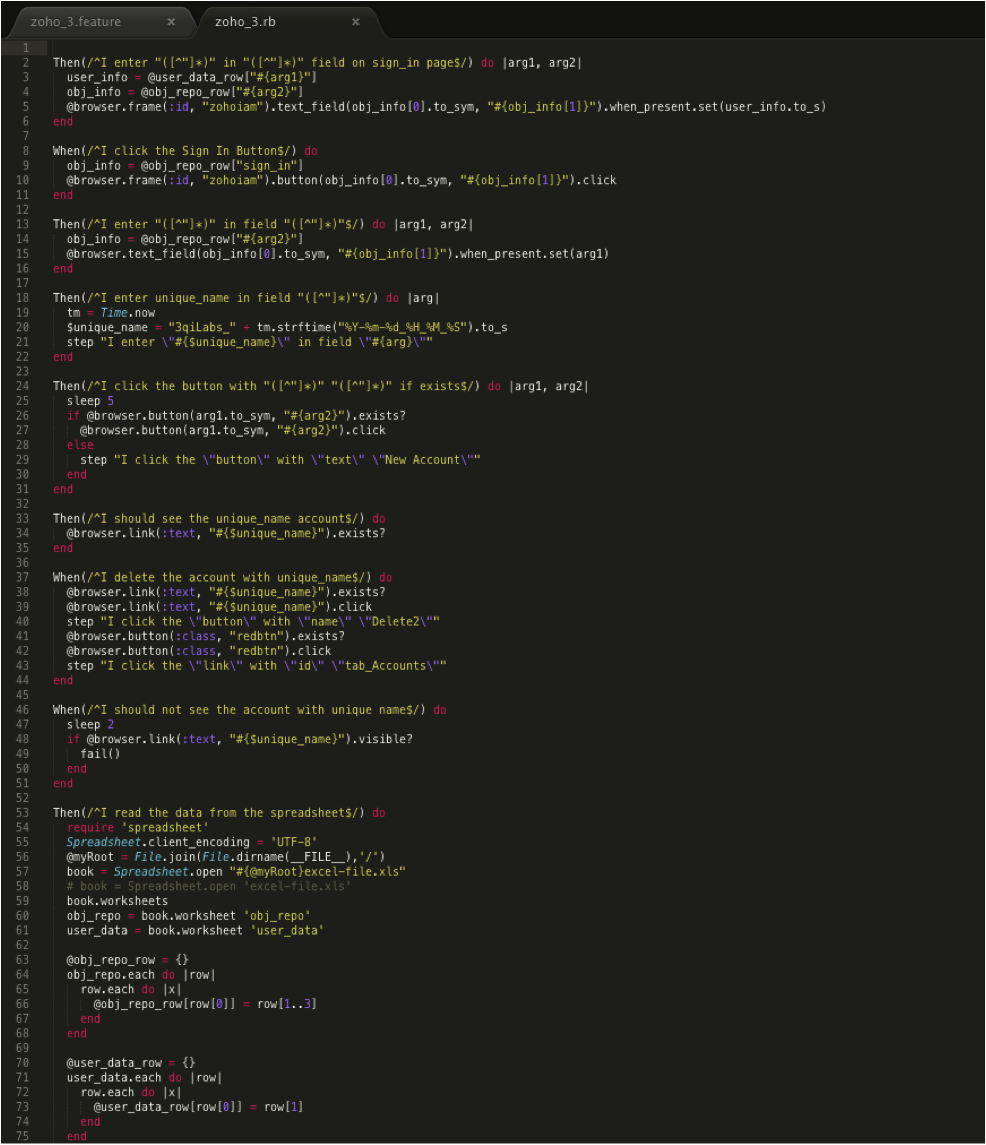 As you can see, by referencing the external data in the script this allows for a relatively short file, when considering using this on a large scale- imagine if we needed to test the same scenario, but for 50+ different leads- that would mean 50+ different combinations of first names, last names, emails, and company names. The script would be endless! And if anyone’s email or any other information changed, the engineer would have to go throughout the whole script and search for the one change they needed to make. That does not sound like an efficient use of time, so this is where the Data-Driven Framework is very useful.
As you can see, by referencing the external data in the script this allows for a relatively short file, when considering using this on a large scale- imagine if we needed to test the same scenario, but for 50+ different leads- that would mean 50+ different combinations of first names, last names, emails, and company names. The script would be endless! And if anyone’s email or any other information changed, the engineer would have to go throughout the whole script and search for the one change they needed to make. That does not sound like an efficient use of time, so this is where the Data-Driven Framework is very useful.